喵!讓我猜猜,你是不是看到有貓咪就點了進來呢?
在繼續閱讀前,點擊下面一張你最中意的貓咪或是狗狗圖片,看看本篇以深度學習技術實作的貓狗辨識 App 能否正確地識別出它們。
當然,你也可以選擇出賣你家的愛貓愛狗,上傳它們的照片。不過別忘了將結果截圖分享給我:)
怎麼樣? App 有正確分類出你選擇的貓咪 / 狗狗嗎?還是你上傳了奇怪圖片,現在正笑著它的迂呢?

如同你所看到的,這個頁面展示了一個以卷積神經網路(Convoluational Neural Network, 後簡稱為 CNN)實作的貓狗圖片辨識應用。你除了可以不斷出賣愛貓愛狗以外,也可以跟著本文,非常直觀地理解以下內容:
- 何謂卷積神經網路 CNN
- 卷積神經網路的運作方式
- 何謂遷移學習
值得事先說明的是,本文雖然有些許 Python 程式碼,但實際上並不會一步步教你寫出一個 CNN(因為網路上已經太多這樣的文章了)。如果這是你的目的,我推薦查看 fast.ai 的圖像分類課程。
本文的目的是讓你在閱讀後對深度學習以及卷積神經網路有個更直觀的理解,並讓你之後的學習之旅更加順遂。
在閱讀本文並對卷積神經網路有個基礎理解之後,你能在文末查看所有我推薦的其他資源,進一步嘗試實作自己的神經網路或是深入學習。
廢話不多說,讓我們開始吧!
神經網路:一個映射函數¶
卷積神經網路(Convoluational Neural Network, 後簡稱為 CNN)是一種神經網路架構,近年在人臉辨識、圖像分類、自動駕駛等領域大放異彩。本篇供你互動的貓狗辨識應用便是基於此所建立的。
雖然 CNN 也能處理文字以及影片輸入,在這篇文章裡頭,我們將特別針對輸入為圖片的例子做說明。一個典型的 CNN 會用以下的方式處理輸入進來的圖片:
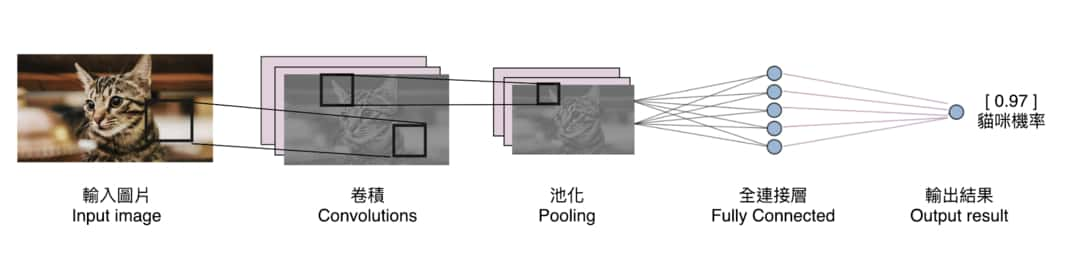
鳥瞰整個流程,就算你現在還不知道何謂卷積或者池化運算,應該也可以看到輸入的貓咪圖片是如何從左到右經過一連串的數據處理步驟,最後被轉換成我們想要的輸出結果的(貓和狗的機率)。
如同我在寫給所有人的自然語言處理與深度學習入門指南中提到的,不管是該篇介紹的循環神經網路 RNN 還是本篇的卷積神經網路也好,拉到最抽象的層次,其實它們做的事情都是一樣的:
任何類型的神經網路本質上都是一個映射函數。它們會在內部進行一連串特定的數據轉換步驟,想辦法將給定的輸入數據轉換成指定的輸出形式。
以本篇的貓狗辨識來說,我們希望針對任意一張貓咪或狗狗的圖片輸入,神經網路都能夠對其像素(pixels)做特定且有意義的轉換,最後回傳給我們正確的貓咪 / 狗狗機率。

既然每個神經網路都是做數據轉換,
「理解不同神經網路所做的數據轉換具有什麼實質意義」這件事情就顯得非常重要了。
畢竟,沒意義的數據轉換如:
- 將圖片裡每兩個相鄰的像素值對調
- 將圖中每個像素值乘以 2 倍
等方式不太可能能像開頭的 App 一樣,幫我們將一張 1024 x 768 像素的貓咪圖片轉換成正確的貓咪機率。

因此,接著就讓我們看看為何當輸入數據為圖片時,卷積神經網路 CNN 中的「卷積運算」是有意義且有效率的轉換。
卷積運算:擷取局部特徵¶
卷積運算裡頭最不可或缺的就是濾波器(filter)的存在了。常見的濾波器大小為 3 x 3 像素,下文皆以此為例。有了濾波器以後,我們會將其用來對圖片中每個對應的 3 x 3 範圍做卷積運算:
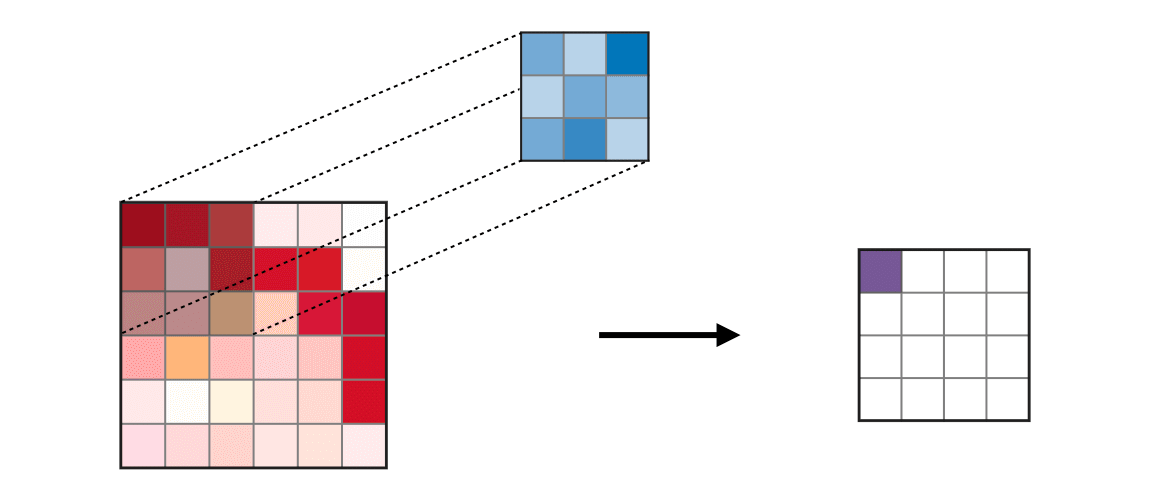
值得注意的是,圖中每次濾波器往右以及往下的距離(stride)為 1,而這是可以調整的。
事實上,卷積就是將濾波器裡頭的每個數字拿去跟圖片對應位置的像素值相乘,再把所有相乘結果加起來:
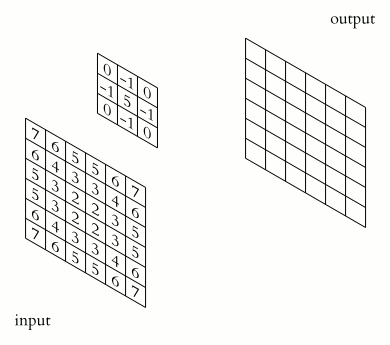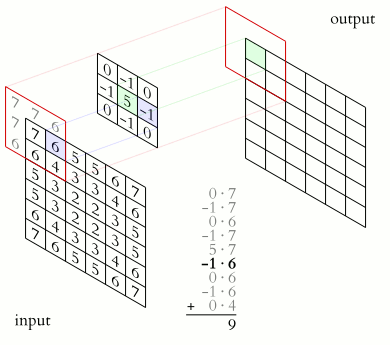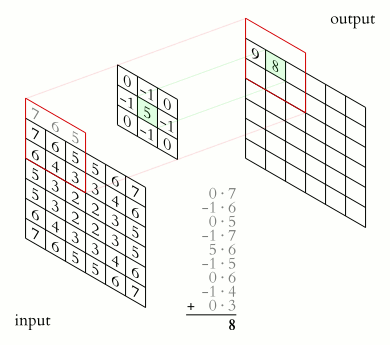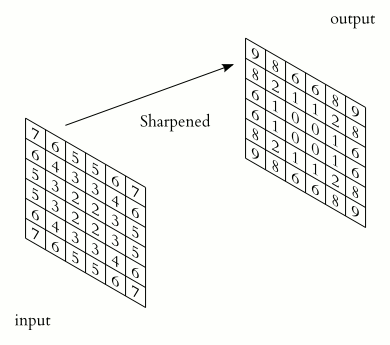
多花一點時間理解上面的動畫,你會發現卷積本身並沒有想像中那麼地困難。但這時你腦中應該會很自然地浮現 1 個問題:
這樣的運算有什麼實質意義呢?

與其聽我解釋,不如先讓你自己實際試試幾個濾波器感受一下。
底下這些濾波器可以用來對你在文章開頭點擊的圖片做卷積運算。現在,透過下拉選單來觀察不同濾波器對該圖的卷積結果吧!
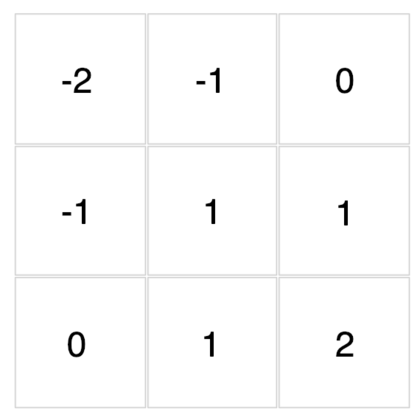
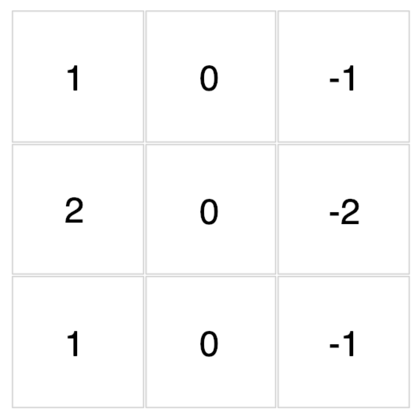
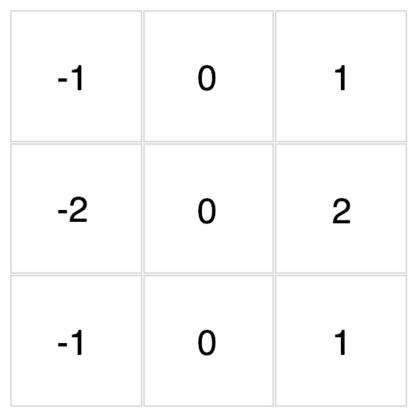
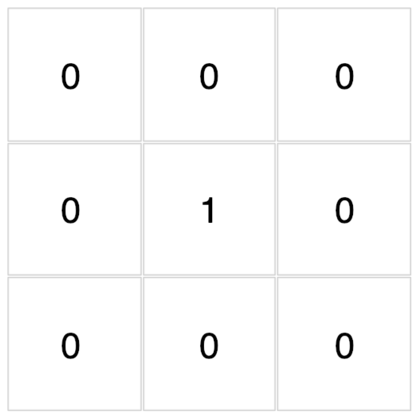
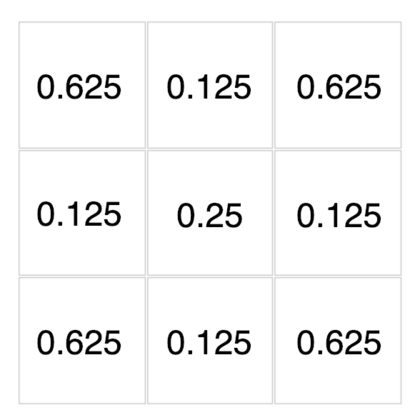
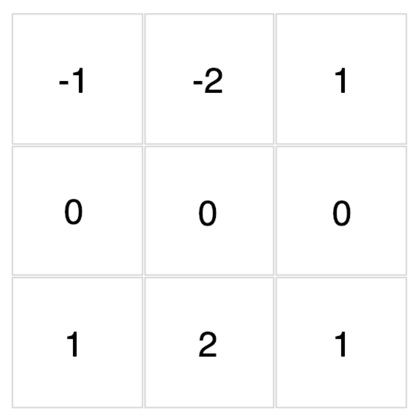
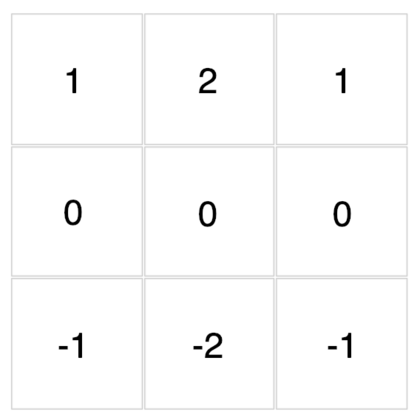
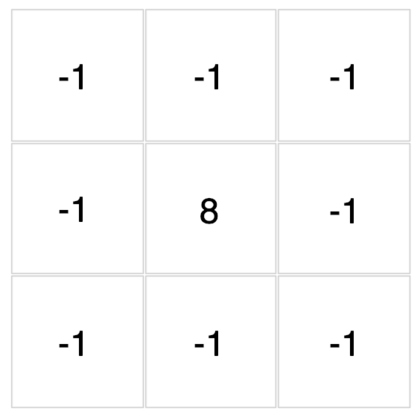
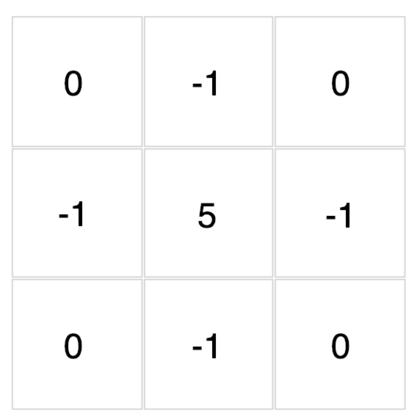









{kind=link}
怎麼樣?我想你現在應該能比較直觀地感受濾波器與卷積運算在做些什麼了。
除了視覺上的娛樂效果以外,每個濾波器對輸入圖片做的卷積運算事實上是一種特徵提取(feature extraction)步驟。
不同的濾波器會對圖中所有相同範圍(3 x 3)的像素做不同的轉換,進而從這些像素裡頭提取出:
- 物件輪廓
- 左上突出
- 邊緣線條
等等實用且具代表性的圖片特徵。
你可能會問:
為何要用小小的濾波器擷取圖片特徵,而不是使用尺寸跟圖片大小一樣的濾波器呢?
答案也十分直覺,因為:
- 每張圖片大小不一,就像我無法預測你上傳的圖的大小一樣
- 很多圖片特徵並不跟原圖大小相同,而是更小的 pattern
- 同樣 pattern 可能重複出現在不同圖中的不同位置

透過使用小的濾波器,我們可以更有效率地擷取重複出現的圖片特徵。
畢竟,我們想要的是一個不管「貓耳」在哪張圖片的哪個位置都能有反應的濾波器,而不是一個只會對「特定位置」的貓耳有反應的濾波器。
另外有趣的是,我們可以將第一組濾波器的輸出結果當成新的輸入「圖片」,接著使用另外一組新的濾波器,再次對這些新的輸入做卷積。
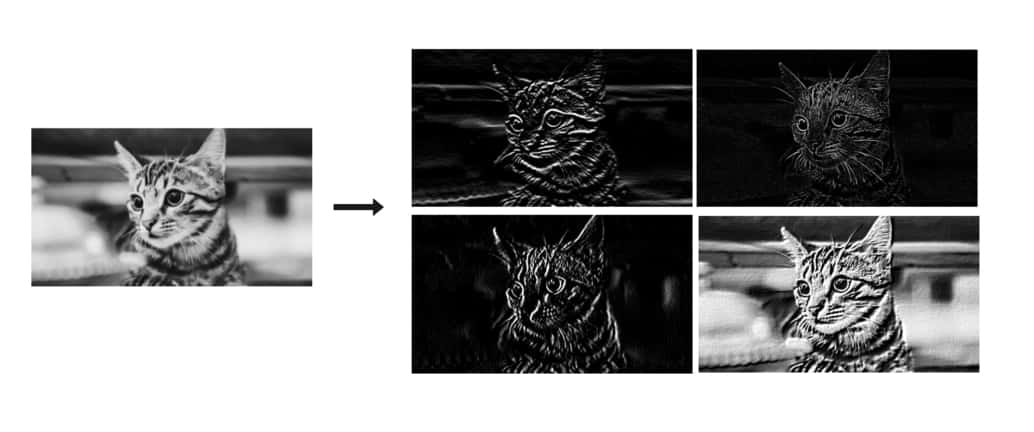
新的運算結果讓我們提取出新的特徵,並再次成為下一組濾波器的輸入。透過重複幾次這樣的轉換,我們相信最終得到的圖片特徵能夠包含原始圖片中的重要資訊。
我們可以利用這些特徵(features)來做很多事情,比方說丟給輸出為一個神經元的全連接層做二元分類(binary classification),進而產生圖片裡有貓咪或狗狗的機率。事實上,這就是本文的卷積神經網路 CNN 在做的事情:
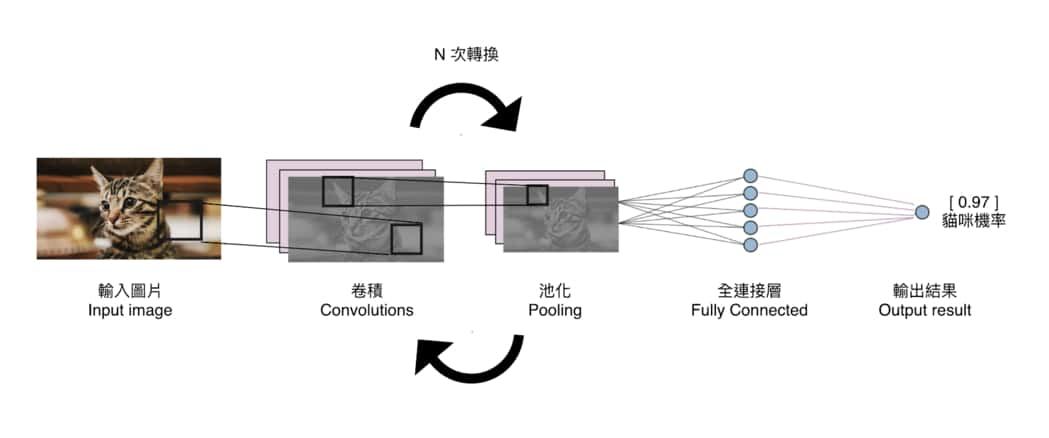
看到這邊,你可能會問另外一個問題:
CNN 裡頭這些濾波器的值從哪來的?前面的濾波器因為我們已經知道它們的值,所以當然可以直接拿來做卷積,但是在 CNN 裡頭,我們不可能手動一個個設定濾波器裡頭的值吧?
非常好的問題。
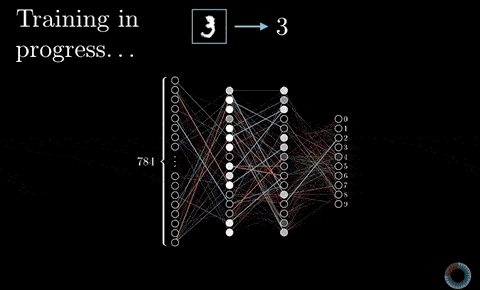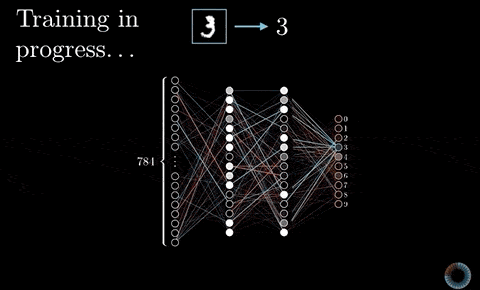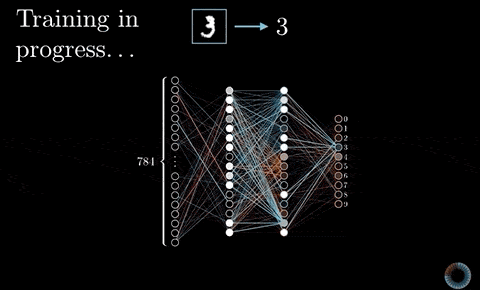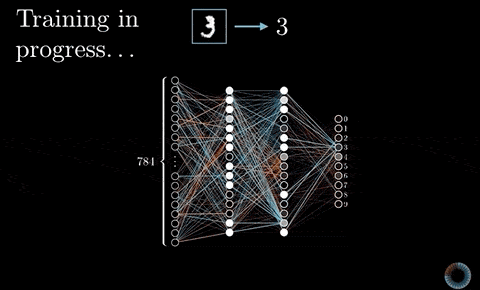
如同我在以前文章說過的,我們可以隨機初始化所有濾波器的數值,並利用平常訓練神經網路的反向傳播算法(Backpropagation),讓 CNN 自己學出一組有用的濾波器數值來將輸入圖片(一大堆像素)轉換成我們想要的值(一個貓咪機率)。
透過這些轉換,CNN 能幫我們萃取出有用的圖片特徵。而這也是深度學習最厲害一個的地方:自動化特徵工程(feature engineering)。
好啦,到此為止,相信你已經充分了解 CNN 裡頭最核心的數據轉換步驟:卷積的運作方式了。
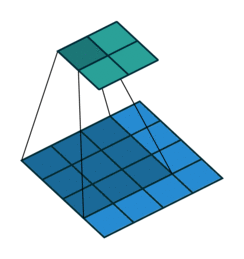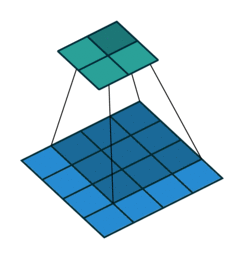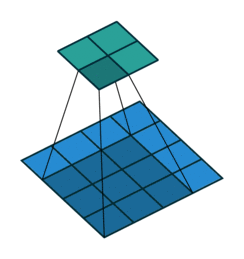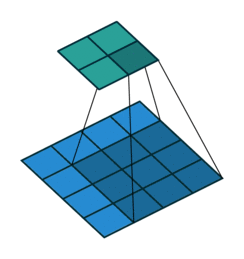
了解 CNN 裡頭最重要的卷積以後,接著讓我們看看出現在卷積後面的池化運算(pooling)吧!
池化運算:降低取樣¶
在了解卷積以後,池化(pooling)的運作方式就很容易理解了。進行池化時,我們一樣會有一個濾波器(filter)掃過整張圖片,但這個濾波器跟卷積時的濾波器不同的地方有幾點:
- 一般來說池化的濾波器大小為 2 x 2(卷積濾波器的大小通常為 1, 3, 5)
- 濾波器每次往右、往下移動距離(stride)為 2(卷積通常為 1)
- 濾波器裡頭本身沒有數值,而是將 2 x 2 範圍裡頭的最大值取出來(卷積則是透過自己的數值跟輸入做相乘計算)
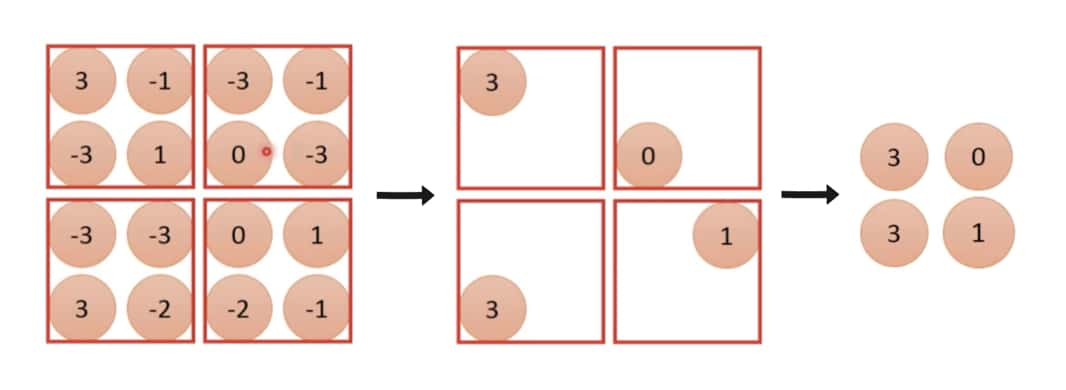
上圖 2 x 2 的紅框即為池化時用的濾波器。而將每個範圍內最大數值取出的 max pooling 是最常見的做法,但你也可以選擇取 4 個數字平均的 average pooling。
以動畫表示池化運算的話就如下方所示:
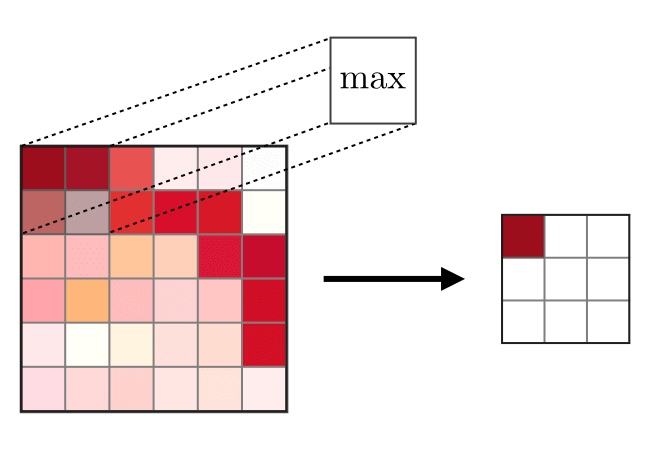
跟解釋卷積運作原理時一樣,池化運算本身不難,事實上這就是對圖片降低取樣(downsampling):取每個子區塊的最大值並降低整體圖片像素數量。
但你可能會問:
這樣的運算有什麼效果呢?
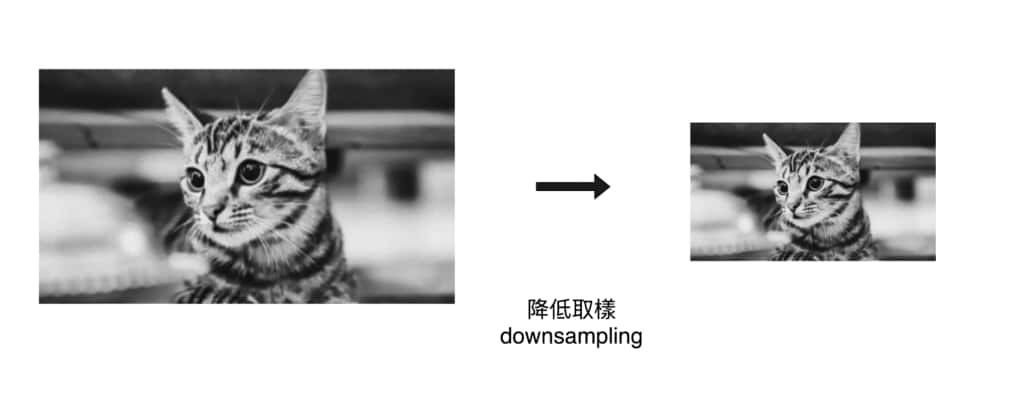
直觀來說,一個 2 x 2 的池化運算能讓我們在不影響物體的情況下,將原圖大小縮減到原來的 25 %。
對你而言,左邊和右邊的圖片都代表著同一隻貓咪。透過池化,我們將圖片特徵數量縮減到 25 % 並保留原先資訊。這樣做最明顯的好處是能減少神經網路所需處理的像素與計算量,加快模型的訓練速度。
好啦,到此為止你已經掌握了 CNN 裡頭最重要的卷積以及池化運算概念了。
讓我幫你把目前為止提到的重要概念做個懶人包:
- CNN 是一個利用卷積與池化對輸入圖片做特徵擷取的神經網路架構
-
對圖片做卷積是有意義的數據轉換是因為:
- 很多圖形 pattern 尺寸比原圖小很多
- 同樣 pattern 會重複出現在很多地方
-
對圖片做池化是有意義的數據轉換是因為:
- 對像素降低取樣並不會改變圖中物件
- 減少神經網路所需處理的數據量
- 卷積後常跟著池化運算,而你可以重複做(卷積 -> 池化)步驟多次來萃取圖片特徵
- 最後得到的圖片特徵可以交給 CNN 裡的全連接層,由它為我們做(貓狗)分類
- CNN 裡的卷積、池化扮演著萃取特徵的角色,而全連接層則扮演著分類器的角色

有了這些知識以後,我想可以向你說明本頁面展示的 App 使用的神經網路架構了。
站在巨人肩膀:遷移學習¶
依照我們前面對 CNN 的說明,要實作貓狗分類,可以使用類似下面的架構:
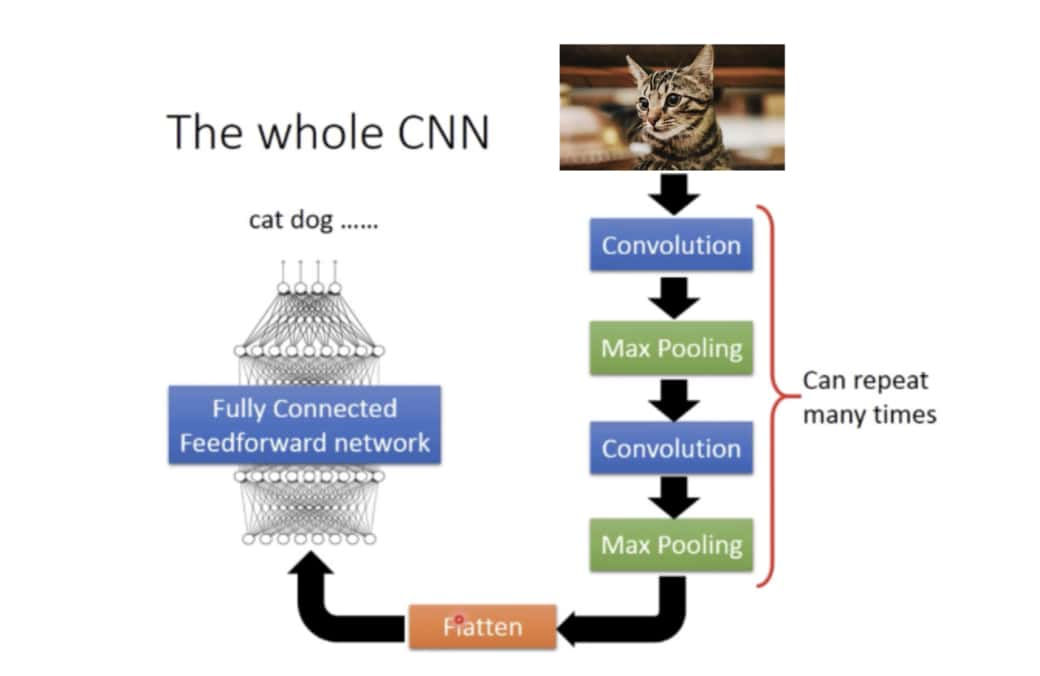
你可以把這個 CNN 拆成左右兩個區塊理解:
- 右側的卷積、池化從原始圖片擷取圖片特徵
- 左側的全連接前饋網路將該特徵拿去做分類
這個架構當作圖像分類的 Hello World 練習沒有問題,但這模型的準確度可能不高。主要有兩點原因:
- 你手邊的貓狗圖片通常不多(幾千張),而當你把這些圖片拿去給這個 CNN 訓練時,它右側的特徵擷取部分(尤其是卷積中的濾波器)可能還沒辦法學到非常有用的數值。
- 這個模型事實上很「小」,做的數據轉換步驟可能不夠,無法很好地萃取貓狗特徵

為了進行更有效的圖片特徵擷取,實務上會使用其他人在大型資料集(比方說有一千多萬張圖的 ImageNet)訓練得到的模型結果。我們可以利用已訓練的 CNN 裡頭的濾波器來擷取自己圖片的特徵,再交給原來的分類器做分類:
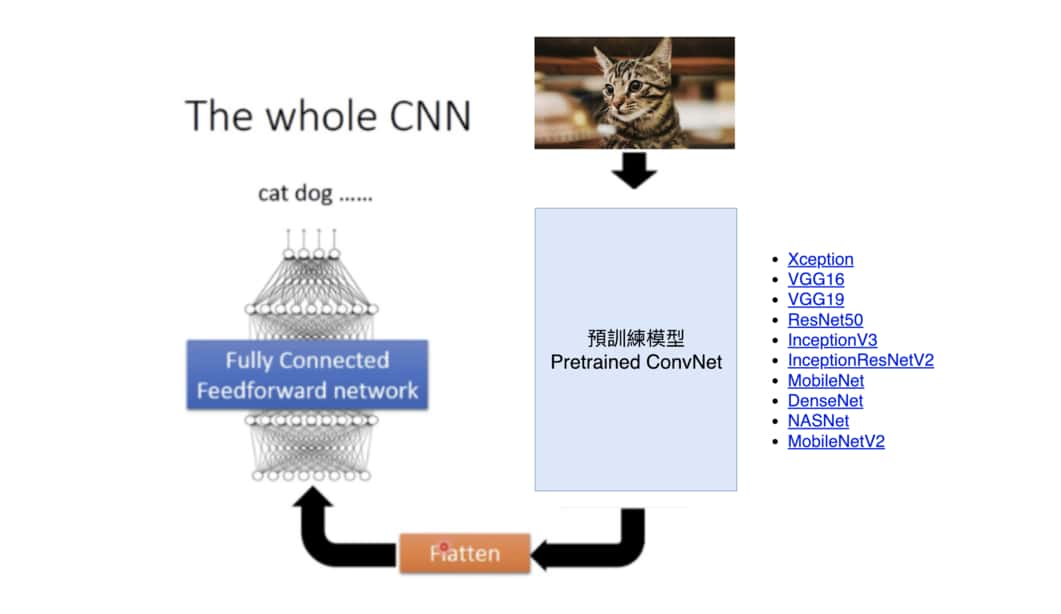
將已經訓練好的模型拿來應用在其他學習任務,就是深度學習中常常在說的遷移學習(Transfer Learning),也是學習深度學習時必備的一個技能。
我們不會深入探討細節,但本文的 App 使用 ShuffleNet V2 來為貓狗圖片做特徵擷取。從 ShuffleNet V2 得到的圖片特徵再交給一般的全連接神經網路做分類預測。
讓我們回顧一下你在本文開頭選擇的圖片:
現在,我們可以將此圖片在 CNN 內部被卷積 / 池化過後的結果顯示出來,看看 CNN 是怎麼為這張圖片做特徵擷取的:

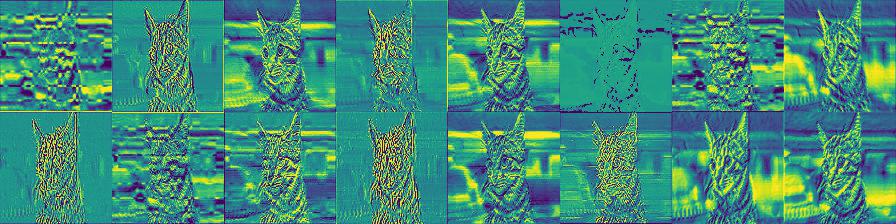

在這邊,我們只顯示 CNN 裡頭前幾層的運算結果,由淺到深。
除了可以發現 CNN 不但自己學到一些有用的濾波器以外,你還可以觀察到深度學習模型一個非常重要的特性:當深度越深,萃取出來的特徵越抽象。而這也是本文最想跟你分享的概念。
實際上,這呼應到文章開頭所說的:
任何類型的神經網路本質上都是一個映射函數。它們會在內部進行一連串特定的數據轉換步驟,想辦法將給定的輸入數據轉換成指定的輸出形式。
你沒辦法簡單寫一個 Python 函式 f(x) 在一個步驟裡頭將輸入圖片轉換成貓咪機率,但你可以將一個已訓練好的 CNN 當作 f(x),並透過它將輸入圖片的像素 x 經過一連串的數據轉換(卷積、池化、全連接層)逐漸轉換成一個貓咪機率 y。
每過一層轉換,萃取出來的資訊就越來越不像原始像素,而越來越靠近分類結果(貓或狗)。
深度學習就是一個「資訊提煉」的管道。透過不斷的數據轉換步驟,將原始數據中不重要的資訊篩去,並把對眼前任務重要的資訊留下來。
這個「資訊提煉」的過程有點類似人類觀察周遭世界的方式。當你看了一隻貓幾秒鐘以後,就算叫你馬上把那隻貓畫出來,你大概也只能記得那隻貓「抽象」的樣子,而不能記住全部細節:

結語:培養對深度學習的更深理解¶
如果你耐心地閱讀到這邊,恭喜你!現在的你應該已經對被廣泛應用在人臉辨識、自動駕駛以及圖像分類的卷積神經網路有個基礎且直觀的理解了:)
你也應該已經可以體會卷積神經網路裡頭並沒有魔法,而是一個複雜的資料處理架構,蘊含了各式各樣人類觀察世界後得出的巧思。

深度學習近年獲得非常大量的關注,以卷積神經網路 CNN 為基礎的新架構也是層出不窮,令人目不暇給。希望透過這篇文章,能讓更多人直觀地了解 CNN 最核心的概念,並以此為基礎,繼續探索深度學習領域。
我們每個人都應該要對正在改變世界的深度學習有更「深」的理解。
本文最後會列出一些相關連結,供有興趣的你繼續探索深度學習。你現在也可以回到頁面最上方試試其他貓狗圖片,如果有什麼有趣的發現的話,也歡迎跟我分享。
另外,如果你覺得這篇文章有幫助到你或者能幫助到其他人學習的話,也請幫我分享給更多人閱讀。這裡沒有廣告,而你的分享就是對我最大的支持,謝謝!
繼續探索:推薦資源¶
如果你現在對深度學習萌生興趣但不曉得該怎麼開始的話,我會推薦你先查看由淺入深的深度學習資源。裡頭包含了各種利用深度學習的線上 demo、教學課程以及實用工具,適合所有人在裡頭尋寶。
如果你想自己訓練出一個如本章的圖像辨識模型,可以參考 Github 上的 cat-recognition-train。裡頭教你如何使用 TensorFlow 訓練一個 CNN。
如果比起圖像辨識,你對自然語言處理比較有興趣的話,可以查看進入 NLP 世界的最佳橋樑:寫給所有人的自然語言處理與深度學習入門指南。
以下則列出我在撰寫此文時引用或是從中獲得啟發的連結:
好啦大概是這樣,再列下去就跟論文引用一樣了。

如果你有任何回饋,都歡迎留言讓我知道,也別忘了幫忙分享此文,謝謝!
跟資料科學相關的最新文章直接送到家。
只要加入訂閱名單,當新文章出爐時,
你將能馬上收到通知